Alright, I am going to be gun-barrel straight about the specific facility inside Emacs as a mail client and that is called Mu4E. There are others, and I do use them too, but that is not what I should spill over this post. Hence, the confinement.
I have said it before and saying it again, Emacs is a kind of departmental store and houses so many things under one roof. But, it is entirely up to the end user to decide which one to opt for and which one to leave out. I have been careful about that notion, solely driven by the ethos not to bloat the damn thing.
In quest of that, I have learned and inducted some facilities in my Emacs configuration and been using it for some time now. One of them is Mu4E and I kinda like it. Importantly, it does the job for me that I intended to do with it.
If you missed somehow my config towards that specific facility inside Emacs, then let me provide you with exact details about it, right here for your convenience sake…
;;Mu4e setup
(setq load-path (append load-path '("~/.emacs.d/mu/mu4e")))
(require 'mu4e)
(setq user-full-name "Bhaskar Chowdhury"
user-mail-address "unixbhaskar@gmail.com")
(setq mu4e-get-mail-command "getmail"
mu4e-update-interval 300
mu4e-attachment-dir "~/attachments")
(setq mu4e-mu-binary "/usr/local/bin/mu")
This is the basic thing you need to induct in your dot emacs or init.el file to get it working. Change the content of it as per your need.
You are supposed to have getmail installed in the system beforehand to retrieve the mail by it.
But there are more….
;;(require 'org-mu4e)
(require 'mu4e-contrib)
(require 'smtpmail)
(auth-source-pass-enable)
(setq auth-source-debug t)
(setq auth-source-do-cache nil)
(setq auth-sources '(password-store))
(setq message-kill-buffer-on-exit t)
(setq message-send-mail-function 'smtpmail-send-it)
(setq mu4e-attachment-dir "~/attachments")
(setq mu4e-compose-complete-addresses t)
(setq mu4e-compose-context-policy nil)
(setq mu4e-context-policy 'pick-first)
(setq mu4e-view-show-addresses t)
(setq mu4e-view-show-images t)
(setq smtpmail-debug-info t)
(setq smtpmail-stream-type 'starttls)
(setq mm-sign-option 'guided)
Pretty dense, right? But, these damn things bring some integration with the software and interface for convenience. It certainly does not end here, so more to add for the sake of a fully functioning system …so follow..
(use-package mu4e
:ensure nil
:config
(setq mu4e-change-filenames-when-moving t)
(setq mu4e-update-interval (* 10 60))
(setq mu4e-getmail-command "getmail")
(setq mu4e-maildir "~/gmail-backup")
(setq mu4e-sent-folder "/sent")
(setq mu4e-maildir-shortcuts
'( (:maildir "/Inbox" :key ?i)
(:maildir "/Greg(GKH)" :key ?g)
(:maildir "/Linus" :key ?l)
(:maildir "/Andrew_Morton" :key ?a)
(:maildir "/Al_Viro" :key ?v)
(:maildir "/Jonathan_Corbet" :key ?j)
(:maildir "/Paul_E_McKenney" :key ?p)
(:maildir "/linux-kernel" :key ?k)
(:maildir "/Thomas_Gleixner" :key ?t))))
Well, change the inboxes as per mail storage and communication style. But the syntax would be like this for sure.
Few little to add to all of the above pieces, and here they are
;; Mu4e Alerts
(use-package mu4e-alert
:after mu4e
:hook ((after-init . mu4e-alert-enable-mode-line-display)
(after-init . mu4e-alert-enable-notifications))
:config (mu4e-alert-set-default-style 'libnotify))
;; Visual line mode and Flyspell mode
(add-hook 'mu4e-view-mode-hook #'visual-line-mode)
(add-hook 'mu4e-compose-mode-hook 'flyspell-mode)
(setq mu4e-compose-in-new-frame t)
(setq mu4e-compose-format-flowed t
You are good enough to read the commented line to discover what the above stanza is. You are supposed to have libnotify package installed in the system beforehand. And that almost everyone has these days, because, it works other things in the system too. So, good to have that one.
A little bit more adds to the niceties of it..so here they are:
;;Refiling folders
(setq mu4e-refile-folder
(lambda (msg)
(cond
;; messages from Linus go to the /Linus folder
((mu4e-message-contact-field-matches msg :from
"torvalds@linux-foundation.org")
"/Linus")
((mu4e-message-contact-field-matches msg :from
"viro@zeniv.linux.org.uk")
"/Al_Viro")
((mu4e-message-contact-field-matches msg :from
"gregkh@linuxfoundation.org")
"/Greg(GKH)")
((mu4e-message-contact-field-matches msg :from
"akpm@linux-foundation.org")
"/Andrew_Morton")
((mu4e-message-contact-field-matches msg :from
"corbet@lwn.net")
"/Jonathan_Corbet")
((mu4e-message-contact-field-matches msg :from
"paulmck@kernel.org")
"/Paul_E_Mckenney")
;; messages sent by me go to the sent folder
((find-if
(lambda (addr)
(mu4e-message-contact-field-matches msg :from addr))
(mu4e-personal-addresses))
mu4e-sent-folder)
;; everything else goes to /archive
;; important to have a catch-all at the end!
(t "/archive")
)))
So, if you are ever undecided about your mails then you might include a stanza like this, and it will segregate things for you.
Well, we are almost there to get every piece together and run it flawlessly 🙂
;; mu4e marks
(add-to-list 'mu4e-marks
'(tag
:char "g"
:prompt "gtag"
:ask-target (lambda () (read-string "What tag do you want to add?"))
:action (lambda (docid msg target)
(mu4e-action-retag-message msg (concat "+" target)))))
(add-to-list 'mu4e-marks
'(archive
:char "A"
:prompt "Archive"
:show-target (lambda (target) "archive")
:action (lambda (docid msg target)
;; must come before proc-move since retag runs
;; 'sed' on the file
(mu4e-action-retag-message msg "-\\Inbox")
(mu4e~proc-move docid nil "+S-u-N"))))
(mu4e~headers-defun-mark-for tag)
(mu4e~headers-defun-mark-for archive)
(define-key mu4e-headers-mode-map (kbd "g") 'mu4e-headers-mark-for-tag)
(define-key mu4e-headers-mode-map (kbd "A") 'mu4e-headers-mark-for-archive)
Marking the specific mail with some letter for their significance or arrival makes it easy to wade through the thousands of mail(which is what I am accustomed to)with ease. It works as a filter too.
A few nifty things have to be added for the sake of completeness, so here we are almost at the fag end …hold on…
'(mu4e-display-update-status-in-modeline t)
'(mu4e-icalendar-diary-file "~/.emacs.d/OrgFiles/refile.org")
'(mu4e-mu-binary "/usr/local/bin/mu")
Essentially, you have to have mu binary/package installed in the system to all it works. And have to point to the location of the binary.
I do use doom-modeline , so here are a few specific configurations related to that, if you use that thing 🙂
;; Whether display the mu4e notifications. It requires `mu4e-alert' package.
(setq doom-modeline-mu4e t)
It will show you the status of the mail count on the modeline itself. Nice to be notified and shows some visual stuff.
Promise, these are the last few bits…I know it is already long …but I just to make sure it looks complete… 🙂
;; Line number and Column number
(column-number-mode)
(dolist (mode '(org-mode-hook
mu4e-main-mode-hook
mu4e-view-mode-hook
mu4e-compose-mode-hook
mu4e-headers-mode-hook
mu4e-org-mode-hook
(add-hook mode (lambda () (display-line-numbers-mode 0))))
(add-hook 'text-mode-hook #'display-line-numbers-mode)
(add-hook 'prog-mode-hook #'display-line-numbers-mode
Just to make sure, that line number does not show up in the composing buffer and other buffers related to mu4e, because that would be annoying.
Here is something that captures the mail-related stuff ….
;;Org mode stuff
(define-key mu4e-headers-mode-map (kbd "C-c c") 'org-mu4e-store-and-capture
Phew! Finally done with the groundwork and have time to bring up the interface with a keyboard shortcut, so I have this in dot Emacs (it could be different for you)
;; Mu4e shortcut
(global-set-key (kbd "M-m") 'mu4e
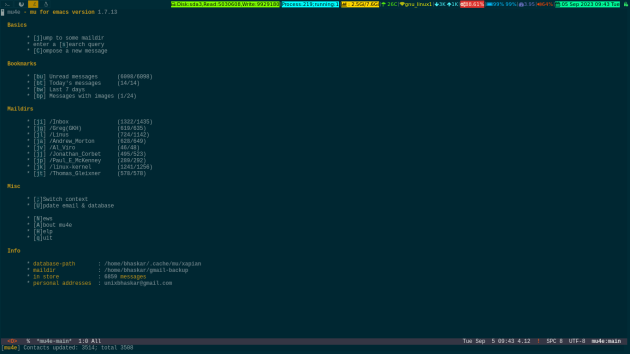
Now for the eye candy stuff to show the actual interface 🙂
You can press the letters in between the [] brackets to get into the corresponding mail dirs or to perform certain actions.
You are encouraged to read this page to get yourself accustomed to this software.